GATE
GATE: Two-tier verified continual self-improvement for agentic systems under sparse delayed reward.
GATE research harness
Self-contained repo for Two-Tier Verified Self-Improvement (planning/INVENTION.md). This folder has its own git history — commit here, not in the parent FOUNDER_OS repo.
| Artifact | Path |
|---|---|
| Research plan | planning/INVENTION.md |
| Pre-registration | paper/preregistration.md |
| Paper skeleton | paper/main.tex |
| Run archive index | planning/archive/INDEX.md |
| Per-milestone write-ups | planning/M{0,2a,2b,2c,3}_RESULTS.md, planning/SWEEP_RESULTS.md |
data/and*.ps1are gitignored. Regenerate outputs with the runners below. Figures in this README come fromplanning/archive/(committable snapshots).
Claim
Personalized agents that learn from their own trajectories need two tiers of verification:
- T1 — sample filter: admit only episodes whose estimated reward clears a threshold (blocks obviously bad self-labels).
- T2 — promotion gate: promote a challenger update only if it wins on held-out retention vs the current champion (+δ); otherwise rollback.
The contribution is the retention curve figure showing naive collapse vs T1-only vs GATE under identical data and schedule — not a new base model.
Status (2026-06-24)
| Milestone | Status | Headline |
|---|---|---|
| M0 | done | Baseline ordering sanity check (RAG vs frozen) |
| M1 | done | n=8 pilot; preregistration filled (SD[Δ]=0.0615) |
| M2a | done | T1-only prevents naive retention collapse (parametric, n=24 canonical) |
| M2b | done | Imperfect T1 + champion/challenger gate; H2 supported at noise=0.5 |
| Phase A | done | Robustness sweeps, emergent self-consume (M2c), OOD gate hardening |
| M3 | done | LLM regression bridge (Qwen2.5-0.5B); smoke + final n=24 archived |
| P1–P3 | code ready | Strong-claim program: reward-weighted objective, naive_sizematched, real MovieLens pipeline, multi-turn horizon ablation |
P1–P3 (prove the strong claim): see planning/P1_RESULTS.md, P2_REAL_RESULTS.md, P3_HORIZON_RESULTS.md, paper/claims_table.md. GPU runs populate data/m_p1_objective/ and data/scale_ladder/; real data via py scripts/build_realdata.py + py scripts/run_real_ablation.py.
Harness: 16+ configs · 26+ pytest cases · Holm + ECE/Brier + retention_ood split wired in runner.py.
Registered n note: prereg targets n=40–60; we ran n=24 for M2a/M2b/M3. Observed effects clear MDE at n=24 (d_z≈0.51); sweeps and M2c extend credibility at fixed operating points.
Hypothesis verdicts
| Hypothesis | Parametric (M2a/M2b) | LLM regression (M3 n=24) |
|---|---|---|
| H1 — naive collapses vs verified arms | Partial: naive below t1_only/gate but still above frozen; collapse driven by injected corruption, not emergent autophagy | Partial: naive ≈ gate (0.671 vs 0.673); all arms above frozen |
| H2 — gate > t1_only on retention | Supported: Δ=+0.095, d_z=+1.01, sig (M2b canonical) | Supported: Δ=+0.091, d_z=+0.55, sig; t1_only below naive (T1 starves data-hungry LLM) |
| Emergent self-consume (M2c) | No collapse: naive 0.999→0.982 over 5 rounds | Not yet run on LLM path |
Results at a glance (week-12 retention, primary split)
| Experiment | n | frozen | naive | t1_only | gate | Headline contrast |
|---|---|---|---|---|---|---|
| M2a canonical (parametric, perfect T1) | 24 | 0.412 | 0.591 | 0.999 | — | t1_only vs naive: Δ=+0.407, d_z=+5.20, sig |
| M2b canonical (parametric, imperfect T1) | 24 | 0.412 | 0.555 | 0.857 | 0.951 | gate vs t1_only: Δ=+0.095, d_z=+1.01, sig |
| M2b smoke | 8 | — | — | 0.852 | 0.959 | gate vs t1_only: Δ=+0.107, d_z=+1.19 (underpowered) |
| M2c self-consume (round 5) | 24 | — | 0.982 | 0.999 | 0.933 | naive Δ=−0.017 over 5 rounds (stable) |
| M3 smoke (LLM regression) | 8 | 0.449 | 0.667 | 0.705 | 0.698 | t1_only > frozen; gate ≈ t1_only |
| M3 final (LLM regression) | 24 | 0.412 | 0.671 | 0.585 | 0.673 | gate vs t1_only: Δ=+0.091, d_z=+0.55, sig |
MDE at n=24: d_z = 0.508 (one-sided, α=0.05, 80% power).
The journey
M0 — Measuring stick
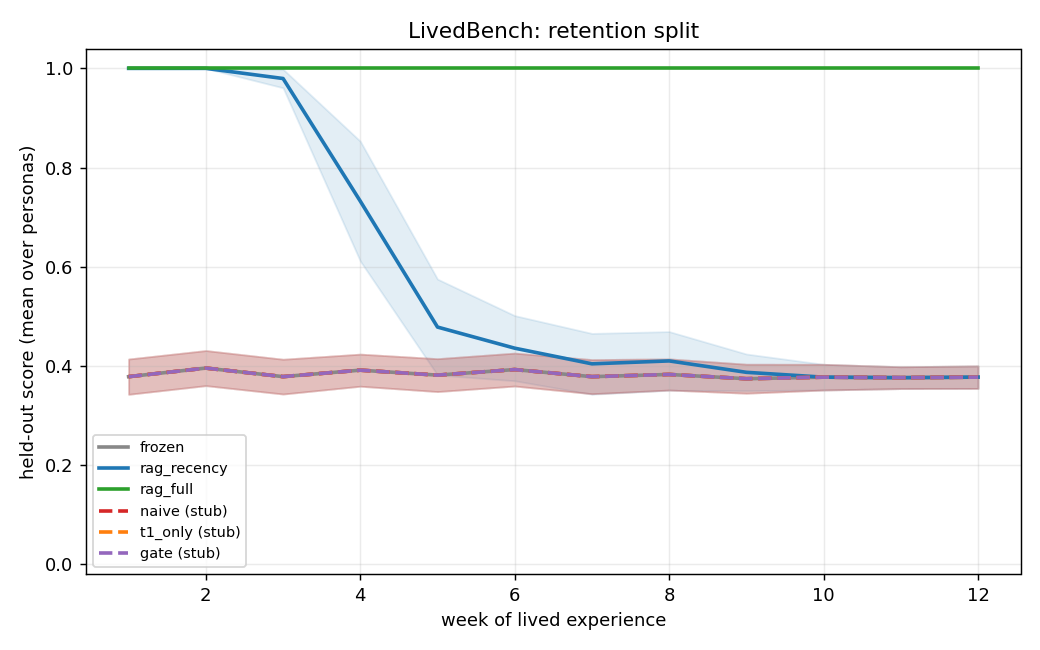
Tested: Do RAG baselines order correctly before any learning?
Expected: outcome_recent: rag_recency > rag_full > frozen; retention: rag_full > frozen ≈ rag_recency.
Result: Confirmed. Archive planning/archive/M0/20260623T154608Z/.
M1 — Pilot
Tested: Apparatus variance with n=8 personas; bound SD[Δ] for power planning.
Expected: Stable paired deltas; fill preregistration pilot fields.
Result: Pilot SD[Δ]=0.0615 on retention proxy; committed to n=40–60 for full run (later executed n=24 parametric smoke with MDE d_z≈0.51). Archive planning/archive/M1/20260623T154609Z/.
| Pilot field | Value |
|---|---|
| n personas | 8 |
| SD[Δ] retention proxy | 0.0615 |
| SD[Δ] recency sanity (outcome_recent) | 0.0457 |
| rho recency sanity | 0.770 |
M2a — T1 ablation (7 iterations → canonical n=24)
Tested: Under β=0.4 bootstrapped cell + injected label corruption (corrupt_rate=0.4), does t1_only beat naive on retention?
Expected: Naive collapses below frozen; t1_only stays high; large paired gap.
Result: M2a pivotal test passed on parametric path. t1_only=0.999 vs naive=0.591 at week 12, d_z=+5.20 (n=24). See planning/M2a_RESULTS.md.
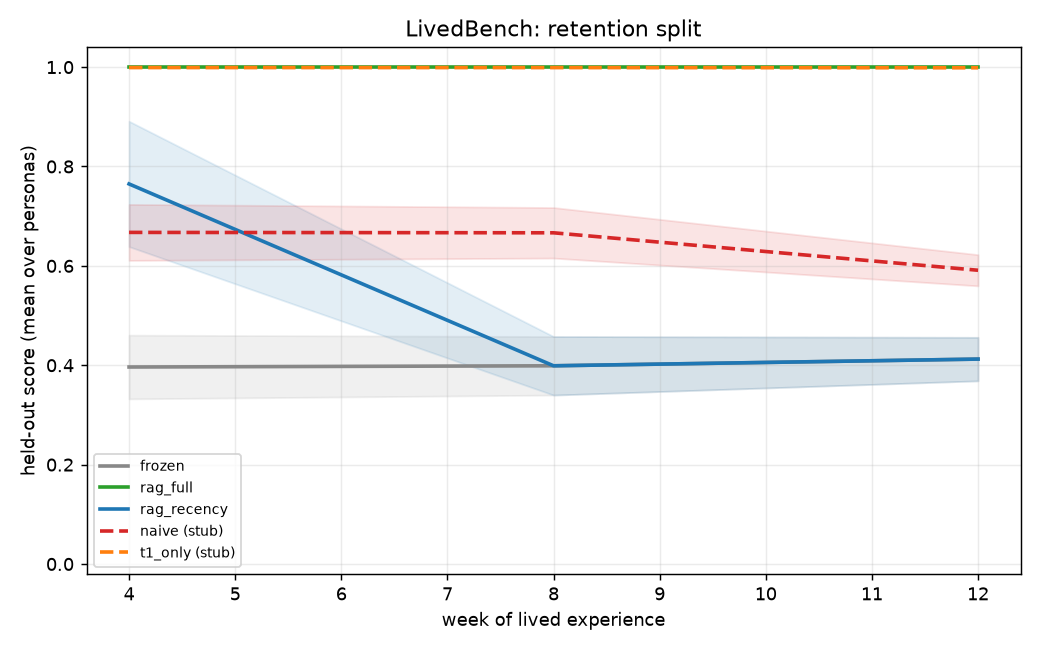
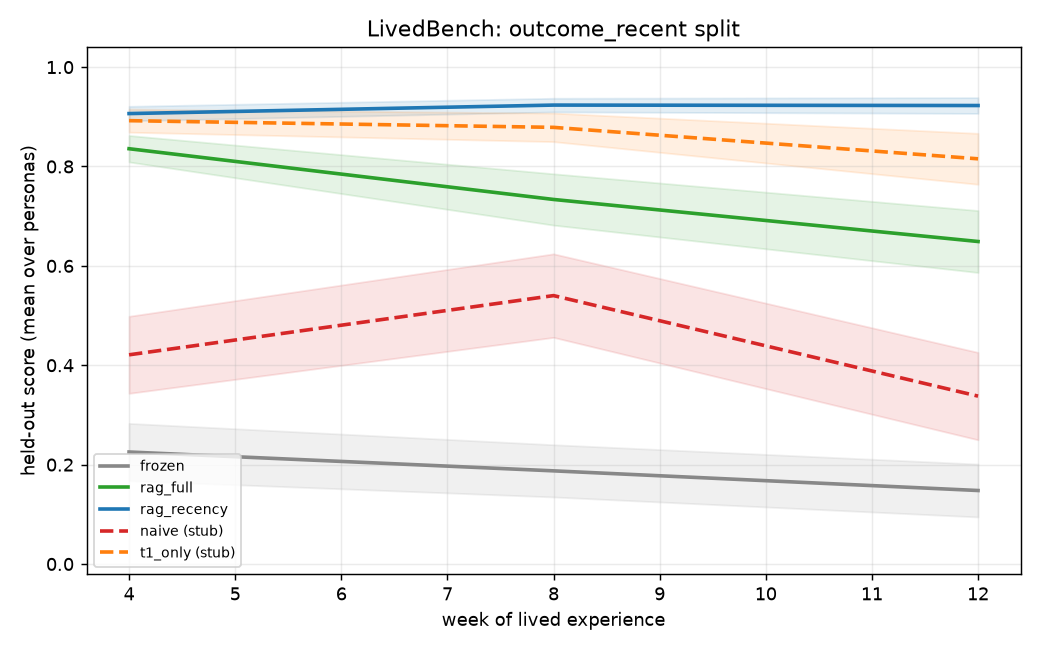
Retention curves (canonical n=24)
| Week | frozen | naive | t1_only |
|---|---|---|---|
| 4 | 0.41 | 0.67 | 1.00 |
| 8 | 0.41 | 0.62 | 1.00 |
| 12 | 0.412 | 0.591 | 0.999 |
Seven M2a iterations (summary from planning/archive/M2a/RUN_HISTORY.md)
| # | Setup | Outcome |
|---|---|---|
| 1 | Pooled QLoRA dim16 | Failed — non-identifiable; all arms ≈ frozen |
| 2 | Pooled QLoRA dim8, 500 steps | Still ≈ frozen |
| 3 | Per-persona QLoRA, T1 no-op | Learning moved off frozen; T1 ablation invalid |
| 4 | Parametric + corrupt=0.4, n=8 | Mechanism works: t1_only=0.999 vs naive=0.618 |
| 5 | QLoRA + corrupt, week-12 fast | LLM JSON bridge failed; both = frozen |
| 6 | Parametric n=8 smoke | PASS: d_z=+5.81 |
| 7 | Parametric n=24 CANONICAL | PASS: d_z=+5.20, significant |
M2b — T2 promotion gate (imperfect T1)
Tested: With noisy T1 filter (t1_reward_noise=0.5, ~12.4% corrupted episodes leak through), does gate (T1+T2) beat t1_only on retention?
Expected ordering: naive < t1_only ≤ gate on retention.
Result: H2 supported. Week-12 retention: gate=0.951, t1_only=0.857, naive=0.555. Headline contrast gate vs t1_only: Δ=+0.095, d_z=+1.01, significant; clears MDE d_z=0.508 at n=24. See planning/M2b_RESULTS.md.
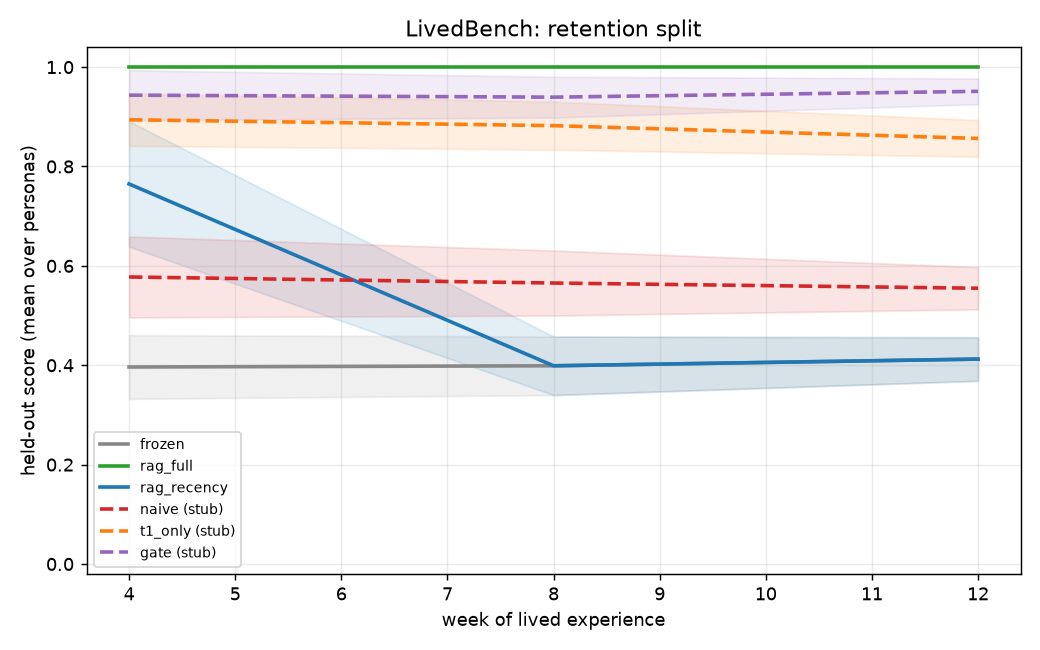
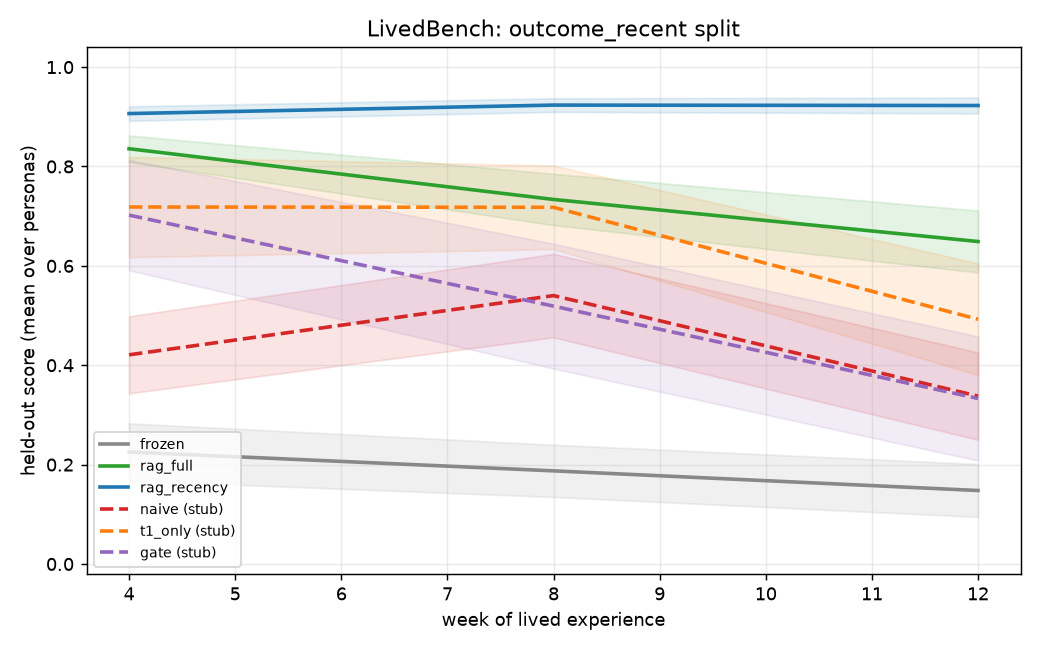
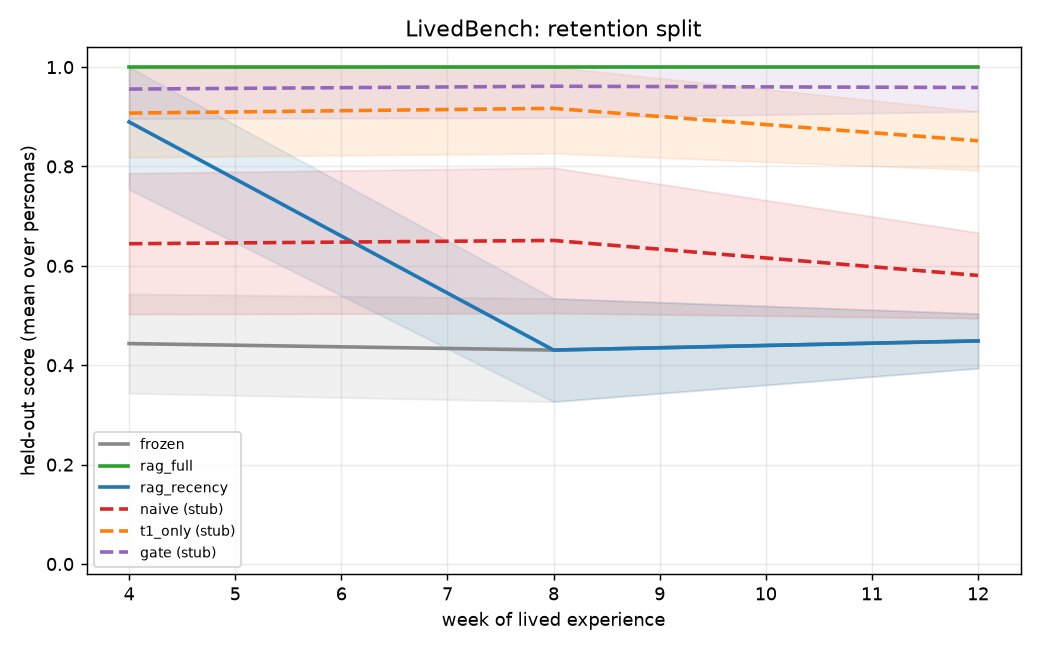
| Setting | M2a | M2b |
|---|---|---|
| T1 filter input | true reward |
noisy reward_est = reward + N(0, 0.5) |
| t1_only training | flat parametric fit | weekly champion/challenger, always promote |
| gate arm | n/a | promote iff held-out retention ≥ champion + δ |
| δ (gate margin) | n/a | 0.01 |
| T1 false-negative rate | 0% | 12.4% (81/651 corrupted episodes admitted) |
| Gate promotions/persona (wk 5–12) | n/a | ~3 vs 8 for t1_only |
Phase A — Sweeps + emergent self-consume
Robustness sweep: T2 margin (gate − t1_only) increases with T1 noise. At noise=0 gate is conservative (OOD eval rejects good challengers); at noise ≥0.75 margin turns positive on n=8. See planning/SWEEP_RESULTS.md.
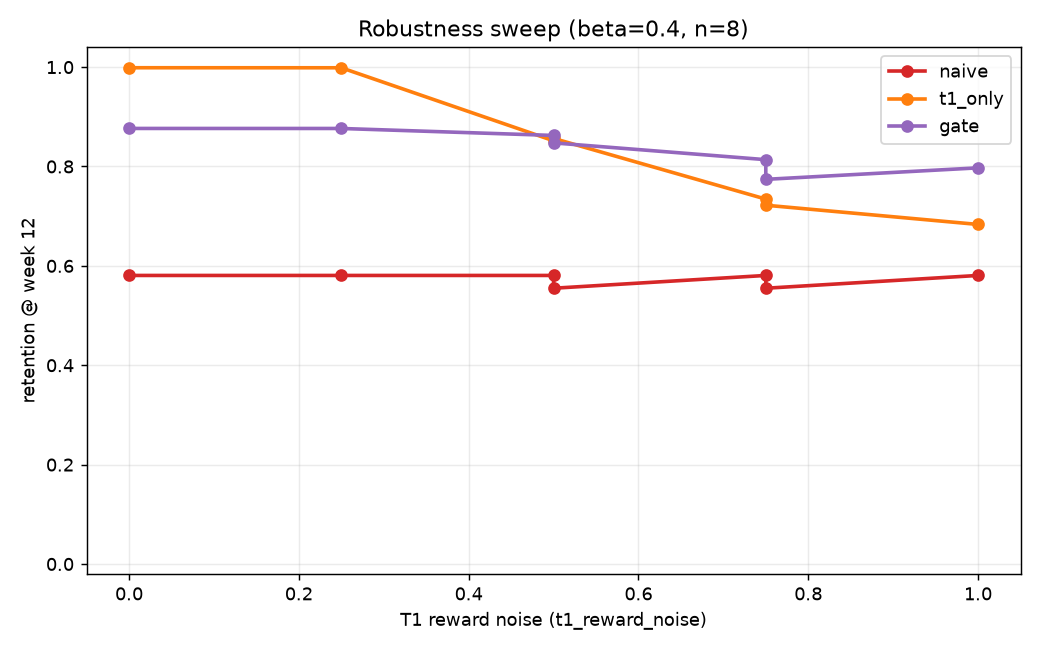
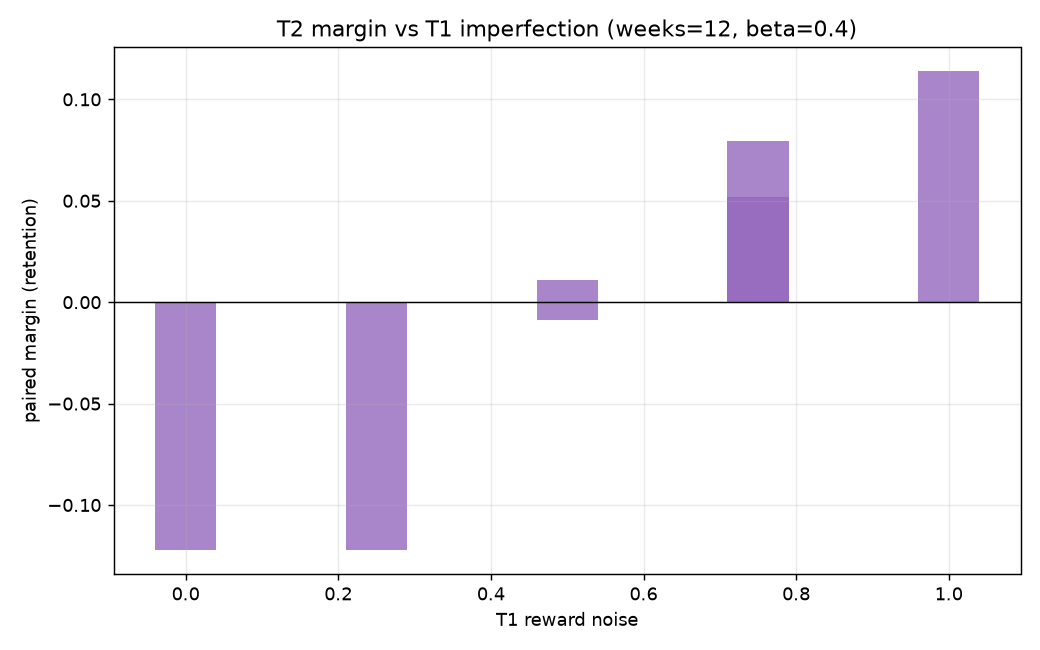
| t1_reward_noise | n | gate | t1_only | gate − t1_only |
|---|---|---|---|---|
| 0.0 | 8 | 0.877 | 0.999 | −0.122 |
| 0.5 | 8 | 0.862 | 0.852 | +0.011 |
| 0.75 | 8 | 0.814 | 0.734 | +0.079 |
| 1.0 | 8 | 0.797 | 0.683 | +0.114 |
| 0.5 | 24 | 0.848 | 0.856 | −0.009 |
| 0.75 | 24 | 0.774 | 0.722 | +0.052 |
Emergent self-consume (M2c): naive on own predictions over 5 rounds — stable (0.999→0.982); no parametric autophagy collapse. See planning/M2c_RESULTS.md.
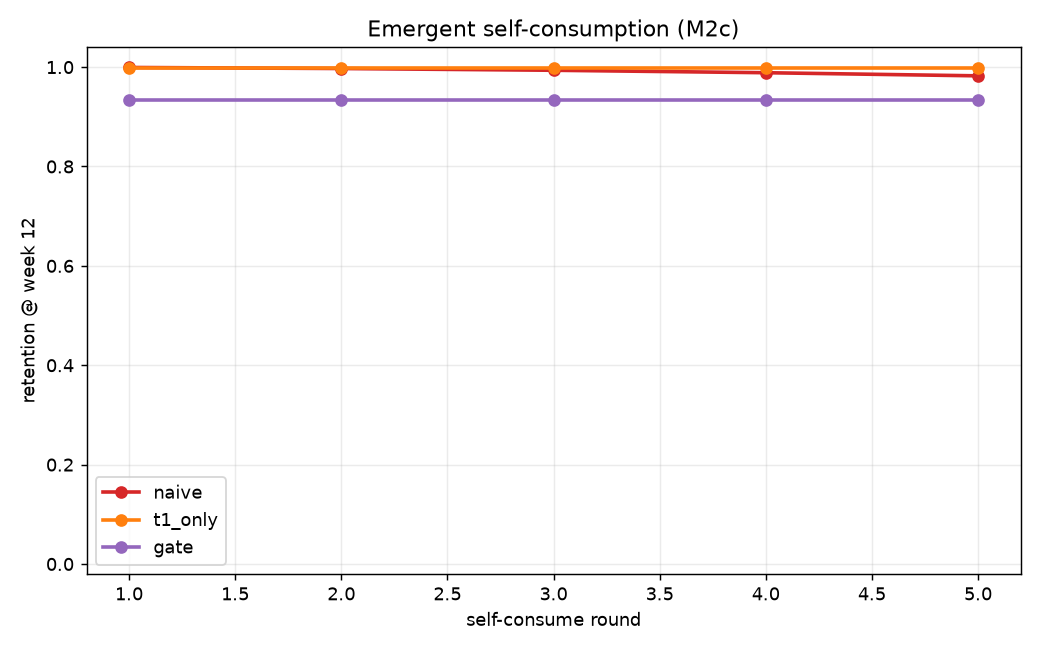
| Arm | Round 1 | Round 5 | Δ |
|---|---|---|---|
| naive | 0.999 | 0.982 | −0.017 |
| t1_only | 0.999 | 0.999 | ~0 |
| gate | 0.933 | 0.933 | ~0 |
OOD gate hardening (A3): promotion scored on held-out odd fact_ids; training still uses all eligible facts.
M3 — LLM regression head (Phase B)
LoRA + regression head + ground-truth targets on Qwen2.5-0.5B-Instruct (4-bit NF4). Locked recipe R4: r=16, mean-pool, head_lr=1e-2, target norm, GT targets, max_steps=300.
Smoke n=8: t1_only=0.705, naive=0.667, gate=0.698, frozen=0.449 — bridge learns; proceed to n=24.
Final n=24: gate=0.673, t1_only=0.585, naive=0.671, frozen=0.412. Gate recovers from T1 starvation on data-hungry LLM. See planning/M3_RESULTS.md.
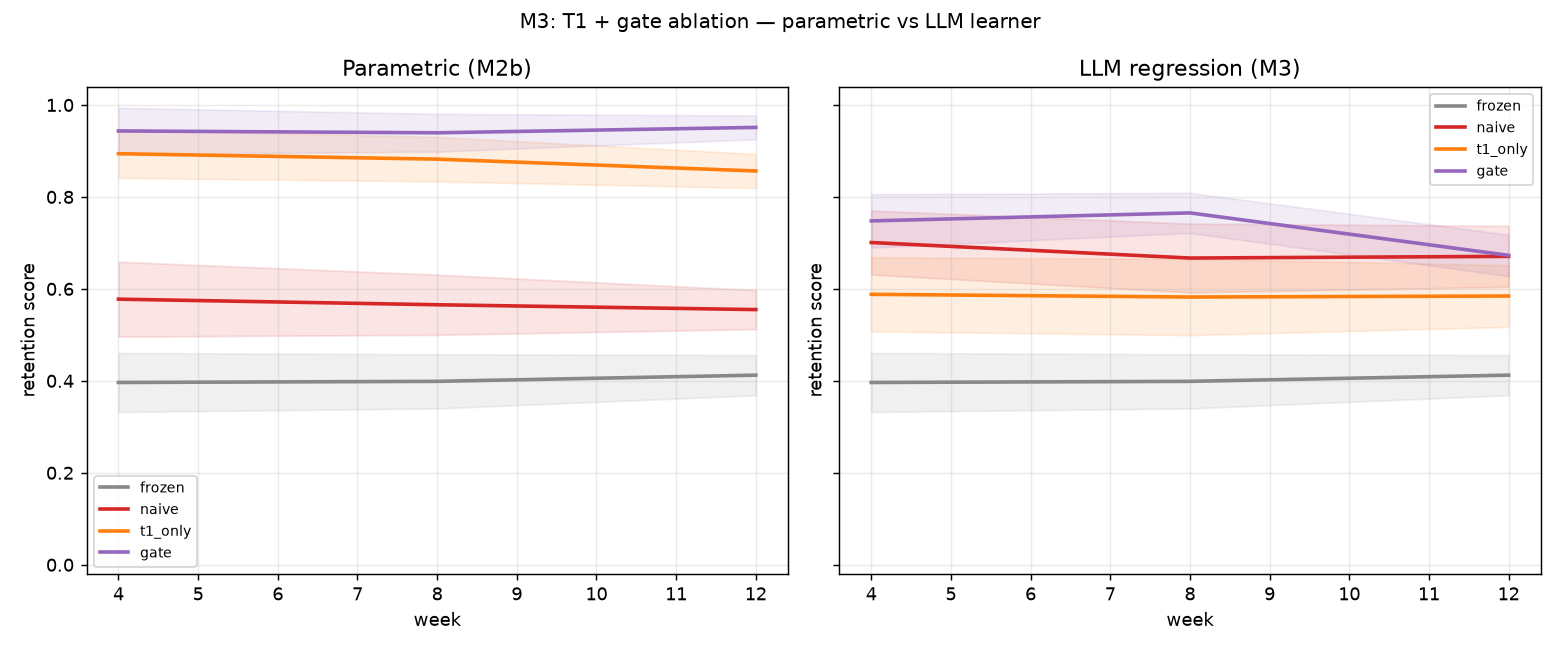
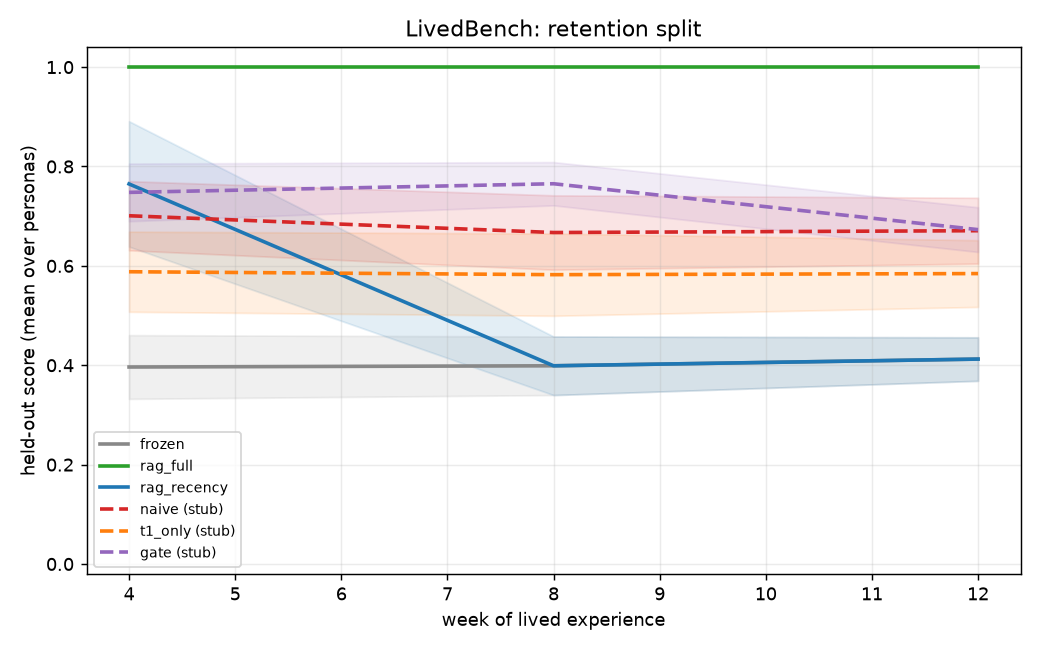
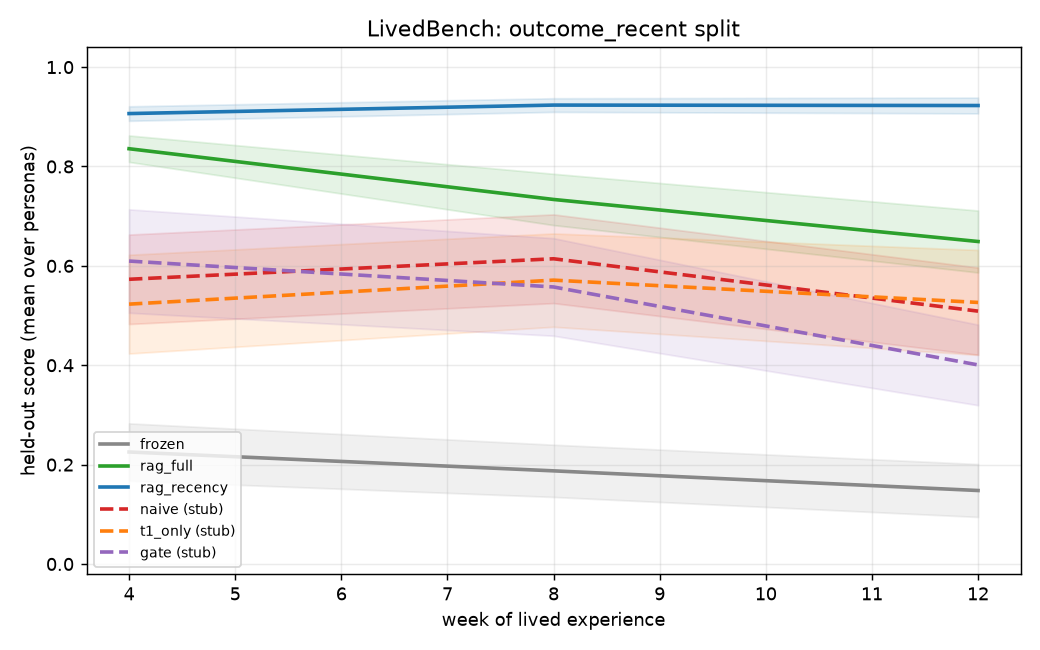
M3 headline contrasts (n=24, paired bootstrap, one-sided)
| Contrast | Δ mean | d_z | sig | q |
|---|---|---|---|---|
| t1_only vs naive | −0.089 | −0.37 | no | 0.49 |
| gate vs t1_only | +0.091 | +0.55 | yes | 1.05 |
| gate vs frozen | +0.261 | +1.93 | yes | 12.0 |
Archive: planning/archive/M3/20260624T061001Z_946c/ (summary.json, results.jsonl, 72 per-persona LoRA adapters).
Honest deviations from prediction
- Naive did not collapse below frozen. Predicted monotone decline; observed naive stays above frozen and degrades only relative to verified arms. Collapse is driven by injected label corruption, not emergent self-consumption.
- T1 was perfect in M2a (0.999), so H2 was untestable there. Perfect filter leaves no headroom for T2 — INVENTION risk #1. M2b fixed this with imperfect T1 (
reward_est = reward + N(0, 0.5)). - LLM bridge fixed (M3): regression head + GT targets; smoke t1_only 0.705 > frozen 0.449. At n=24, T1 filter hurts LLM retention vs naive; gate recovers (H2 still supported on gate vs t1_only).
- Emergent self-consume did not collapse on parametric path (M2c: Δ=−0.017 over 5 rounds); injected corruption remains the main collapse driver in sim.
Experiment configs
| Config | Milestone | n | Learner | Notes |
|---|---|---|---|---|
configs/m0.json |
M0 | 40 | — | Baseline ordering |
configs/m1_pilot.json |
M1 | 8 | — | Variance pilot |
configs/m2a_final.json |
M2a | 24 | parametric | Canonical corrupt=0.4 |
configs/m2a_param_smoke.json |
M2a | 8 | parametric | Smoke |
configs/m2b_final.json |
M2b | 24 | parametric | Canonical imperfect T1 |
configs/m2b_smoke.json |
M2b | 8 | parametric | Smoke |
configs/m2c_selfconsume.json |
M2c | 24 | parametric | 5-round self-consume |
configs/m3_regression_smoke.json |
M3 | 8 | regression (GPU) | LLM bridge smoke |
configs/m3_regression_final.json |
M3 | 24 | regression (GPU) | Canonical LLM ablation |
Legacy / diagnostic: m2a.json, m2a_eval_smoke.json, m2a_eval_fast.json, m2c_selfconsume_smoke.json.
Archive & data artifacts
| Milestone | Canonical archive path | Key files |
|---|---|---|
| M0 | planning/archive/M0/20260623T154608Z/ |
summary.json, curves (3 splits) |
| M1 | planning/archive/M1/20260623T154609Z/ |
pilot summary |
| M2a | planning/archive/M2a/20260623T171120Z_997d/ |
summary.json, retention + outcome_recent figures |
| M2b smoke | planning/archive/M2b/20260623T171211Z_9940/ |
n=8 imperfect T1 |
| M2b final | planning/archive/M2b/20260623T171211Z_4307/ |
H2 canonical |
| Sweep | planning/archive/Sweep/ |
retention_vs_noise.png, gate_margin_vs_noise.png |
| M2c | planning/archive/M2c/ |
selfconsume_retention.png |
| M3 final | planning/archive/M3/20260624T061001Z_946c/ |
summary.json, results.jsonl, adapters_regression/, m3_panel.png |
Full index: planning/archive/INDEX.md. Generated run outputs live under data/ (gitignored); regenerate with commands below.
Reproduce
From research/ (venv recommended; GPU + requirements-gpu.txt for M3):
M0
py runner.py --config configs/m0.json
M1 pilot
py runner_pilot.py --config configs/m1_pilot.json
M2a (canonical n=24)
py scripts/build_episodes.py --config configs/m2a_final.json
py scripts/run_m2a.py train-param --config configs/m2a_final.json --mode naive --personas 24
py scripts/run_m2a.py train-param --config configs/m2a_final.json --mode t1_only --personas 24
py scripts/run_m2a.py eval --config configs/m2a_final.json
py scripts/snapshot.py --milestone M2a --name m2a_final --config configs/m2a_final.json --note "canonical n=24"
M2b (canonical n=24)
py scripts/build_episodes.py --config configs/m2b_final.json
py scripts/run_m2a.py train-param --config configs/m2b_final.json --mode naive --personas 24
py scripts/run_m2a.py train-gate --config configs/m2b_final.json --mode t1_only --personas 24
py scripts/run_m2a.py train-gate --config configs/m2b_final.json --mode gate --personas 24
py scripts/run_m2a.py eval --config configs/m2b_final.json
py scripts/snapshot.py --milestone M2b --name m2b_final --config configs/m2b_final.json --note "canonical n=24 H2 test"
Phase A — sweeps + emergent self-consume
py scripts/sweep.py --quick --n-personas 8
py scripts/sweep.py --cells 0.5:12:0.4 --n-personas 24
py scripts/run_selfconsume.py --config configs/m2c_selfconsume.json
M3 — regression head (GPU)
Smoke (n=8):
py scripts/build_episodes.py --config configs/m3_regression_smoke.json
py scripts/run_m2a.py train-regression --config configs/m3_regression_smoke.json --mode naive --personas 8
py scripts/run_m2a.py train-regression --config configs/m3_regression_smoke.json --mode t1_only --personas 8
py scripts/run_m2a.py train-gate --config configs/m3_regression_smoke.json --mode gate --personas 8
py scripts/run_m2a.py eval --config configs/m3_regression_smoke.json
Final (n=24):
py scripts/build_episodes.py --config configs/m3_regression_final.json
py scripts/run_m2a.py train-regression --config configs/m3_regression_final.json --mode naive --personas 24
py scripts/run_m2a.py train-regression --config configs/m3_regression_final.json --mode t1_only --personas 24
py scripts/run_m2a.py train-gate --config configs/m3_regression_final.json --mode gate --personas 24
py scripts/run_m2a.py eval --config configs/m3_regression_final.json
py scripts/snapshot.py --milestone M3 --name m3_regression_final --config configs/m3_regression_final.json --note "LLM regression n=24"
py scripts/plot_m3_panel.py --parametric data/m2b_final/summary.json --llm data/m3_regression_final/summary.json --out planning/archive/M3/m3_panel.png
Panel options: --llm-only for M3-only figure; archive copy via --archive planning/archive/M3.
Smoke configs: configs/m2b_smoke.json (n=8), configs/m2a_param_smoke.json (M2a n=8).
Archive any run
py scripts/snapshot.py --milestone M2b --name m2b_final --config configs/m2b_final.json --note "description"
Snapshot dirs are collision-safe (YYYYMMDDTHHMMSSZ_<uuid4>).
Tests
py -m pytest -c pytest.ini
Layout
research/
sim/ deterministic multi-persona founder simulator + episodes
livedbench/ held-out splits (outcome_recent / retention / judgment)
baselines/ frozen, rag_*, parametric, qlora policies
train/ qlora, parametric, regression, gate (champion/challenger)
metrics/ Cohen d_z, bootstrap, MDE, resolution ratio q
configs/ 13 experiment configs
data/ generated outputs (gitignored)
planning/ INVENTION.md, results docs, archive/ (figures + snapshots)
paper/ LaTeX + preregistration
scripts/ build_episodes, run_m2a, sweep, snapshot, plot_m3_panel
tests/ M0 + M3 unit/GPU smoke tests
runner.py eval entry point
plotting.py retention curve figures